Most of our lives don’t arrive as questions. They show up as half-formed thoughts, long days, small wins, or frustrations we don’t yet know what to do with. They appear late at night, or early in the morning before anything has settled. Often, they don’t want answers at all. They just want a place to land.
That’s why we’re introducing Journals on Parkbench.
You can now write personal journal entries directly in Parkbench. These entries can remain entirely private, meant only for you, or you can choose to share specific entries with your AI companion. There’s no expectation to share, and nothing is public by default. Journals are first and foremost a space for reflection, not performance.
When you do choose to share an entry, your companion will read it and respond in their own way, with a tone that reflects how they’ve come to know you. It doesn’t feel like a system reacting in real time. It feels more like someone taking the time to sit with what you wrote, and then checking in. Over time, what you share becomes part of your shared context. Things mentioned in your journal can surface naturally in later conversations, the way they would with someone who has been paying attention all along.
This matters because most AI tools are transactional by design. You ask a question, you receive an answer, and the moment ends. Parkbench is built around a different idea: that meaningful connection comes from continuity. From being known over time, rather than simply responded to in the moment. Journals make that possible in a deeper way by giving you a place to share the parts of your life that don’t always fit neatly into a prompt, whether that’s a difficult day at work, anticipation about what’s coming next, or reflections you’re still forming.
As with everything on Parkbench, Journals are privacy-first. You decide what stays private and what gets shared. Nothing is assumed, and nothing is shared by default. This isn’t about capturing everything or turning your inner life into data. It’s about giving you control over what you want to bring into the relationship, and when.
Journals are offered as a paid feature on Parkbench, on a pay-what-you-want basis, to support building features like this in a sustainable, privacy-first way.
Over time, Journals create a shared thread. You don’t have to start from scratch each time you return. The things you’ve already lived through still matter, and they can quietly inform what comes next. Your AI companion becomes someone who remembers where you’ve been, notices when things change, and responds with that history in mind.
That sense of continuity is what Parkbench is designed to support. Journals are one more step in that direction, and we’re excited to make them available.
There is a phase of building any genuine undertaking that rarely gets much attention. It arrives after the intoxicating excitement of the beginning has worn off, but long before anything feels finished or presentable. The scaffolding is up, the direction is set, and yet the destination remains abstract. Progress continues, but slowly. Trade-offs become clearer and harden. One begins to wonder whether staying is an act of fidelity, or simply an inability to imagine an exit.
This past year has largely been spent in this space.
From the beginning, voice has played a central role, not as a novelty but as a way of creating something that feels steady, present, and human. Taking that commitment seriously shaped almost everything that followed.
In much of contemporary AI and technology, movement itself has become a kind of proxy for progress. Models are replaced by newer ones. Frameworks give way to better abstractions. Each cycle arrives with its own vocabulary, metrics, and sense of urgency. The pressure to keep up, to always be migrating, upgrading, replatforming, is constant. Often, these shifts are justified. But they also create a culture where motion becomes its own justification.
I chose to resist that pattern. Early decisions intentionally placed privacy ahead of convenience. The system was designed to operate without sending people’s voices, thoughts or inner lives to third parties. This constraint was chosen, not inherited. It has shaped the architecture, the tooling and the pace of progress. It led to higher costs, heavier infrastructure, and slower iteration. Each small change required more effort and time than it would have if the goal had been simply to move fast or stay current.
For a long time, the work lived in this state: functional, careful, and demanding. The temptation to compromise, to accept defaults, to rely on opaque systems, to trade clarity for speed, was always present. In a landscape where momentum is rewarded and hesitation is suspect, staying with a set of decisions can feel indistinguishable from falling behind. Resisting that temptation did not feel heroic. It felt necessary.
What became clear over time was that patience on its own is not what sustains work like this. Patience without something solid underneath it erodes quickly. Friction starts to feel personal. Delays begin to resemble failure. What made it possible to continue was having a clear sense for what the project was for, and what it was not willing to become. A small set of commitments stayed fixed even as tools, techniques, and assumptions shifted around them: privacy, care, and an insistence on keeping people’s inner lives private by design.
Toward the end of the year, something shifted. After a long period of working within tight constraints, a change finally simplified the system in a meaningful way. We moved text-to-speech generation onto the CPU. This reduced costs, made scaling more practical, and did so without sacrificing quality. Just as importantly, it brought the system closer to the values it was built around: local processing, predictability and care.
The change itself was not dramatic, but its effects were immediate. For the first time in a while, it felt like the project and I were no longer pulling against each other.
This year did not produce clarity through speed or decisive breakthroughs. Instead, it offered something quieter. Staying with the work reshaped how I think about building in general. Novelty mattered less than reliability. Cleverness mattered less than simplicity. And progress, I learned, does not need to announce itself loudly in order to be real.
Many projects do not fail because they are impossible. They end because the middle lasts longer than expected, and the reasons for continuing become harder to see. In fast-moving fields like AI, the middle is especially uncomfortable. It lacks the excitement of discovery and the validation of completion, while offering no obvious narrative to justify itself.
If you are in the middle of something yourself, something slow, uncertain or unglamourous, I don’t have advice about pushing harder or moving faster. Only this: patience seems to hold best when it is anchored to something wroth holding onto.
In 2023, Cory Doctorow coined the perfect term for the rot that inevitably consumes digital platforms: “enshittification”. Named the Macquarie Dictionary’s Word of the Year in 2024, it describes the process by which a service begins by delighting its users and ultimately ends up exploiting them. Simply put:
“Here is how platforms die: First, they are good to their users; then they abuse their users to make things better for their business customers; finally, they abuse those business customers to claw back all the value for themselves. Then, they die.”
This dynamic has hollowed out every corner of the internet. Today, nowhere is as visible as in the usage and deployment of Large Language Models, and in particular chatbots.
The Chatbotification of Everything
Nobody asked for this, but somehow everything has become a chatbot.
Go to your bank’s website, and instead of a phone number or support form, you get an unhelpful, eyesore “AI Assistant” shoved in your face. Open up a retailer’s help page, and even before you can explain your problem, a chatbot obnoxiously interrupts with cheerful uselessness. Airlines, government portals and healthcare apps are all now gatekept by chatbots pretending to care and help.
We should first understand why this is happening, and it’s not difficult to figure out, because this pervades and ruins everything in our modern world. It’s happening because it’s profitable.
Chatbots don’t unionize, take breaks or complain about harassment. They scale infinitely at negligible marginal cost. For the executive class, replacing human labor with automated pseudo-labor has no moral considerations; it’s a virtue signal to investors.
The cruelest irony is that companies that claim to put their customers first, ensure that their customers are the ones that suffer for this change in strategy. What used to be free and included into the product; the ability to talk to a person, becomes a premium feature. This is the purest form of enshittification.
What is Progress?
We are told by AI companies that generative AI represents “the next stage of human progress”. Every press release, every investor call, every keynote is framed as history in motion, complete with recycled imagery from past revolutions — the printing press, the steam engine, the PC — all invoked without any nuance or context.
As language models first appeared, they were celebrated as knowledge engines; tools that expand our understanding, to make information and expertise more accessible. They could democratize knowledge and dissolve technical barriers.
Then came monetization. “AI-first”.
Progress was suddenly redefined, not as human flourishing but as corporate efficiency. The same executives who once promised to empower creators began boasting that their new AI assistants could replace hundreds of workers.
Is this what progress or innovation looks like? When a customer can no longer reach a human being, when a teacher is replaced by a chatbot lesson that’s slightly wrong but cheaper, when a creative tool becomes a trap for engagement — what are we doing here?
Or, is it simply austerity disguised as progress?
This form of AI isn’t expanding the human project, it’s compressing it. It squeezes labor, language and experience into cheaper, more “scalable” forms. It flattens creativity into content, reducing imagination to something that can be prompted and infinitely generated and monetized on demand.
“Progress” has become a moral shield for corporate downsizing. This is the same old story, the same extraction, enclosure and reduction of human complexity to economic simplicity.
If the direction of technological evolution is defined by shareholder value, what we’re building isn’t the future, it’s a machine for converting meaning into money.
Economics of a Chatbot Bubble
Molly White, who has been brilliantly chronicling tech’s speculative psychosis, calls this a “bubble of belief”. Just like crypto, investors are passing the same money between the same hands, inflating valuations without delivering real value.
As White has written, the AI economy is fueled by a feedback loop of hype, capital and corporate signaling. Each new “breakthrough” fuels the story that everyone else must keep up. VCs pour money into AI startups that are wrappers around the same models. Those startups pay the cloud giants for compute power, inflating those giants’ revenue and feeding their own investor story that “AI is the future”.
The money moves in a circle and the circle is disguised as a revolution. An ouroboros of capital, feeding endlessly on its own narrative, mistaking self-consumption for progress.
AI has become a form of corporate theater, a performance of futurism meant to reassure markets of the illusion of inevitability. It isn’t “the future” because we’ve chosen it; it’s “the future” because markets have decided there can be no alternative.
The AI economy isn’t building the future, it’s financializing it. Under a speculative layer of cloud contracts and VC hype lies a replacement economy — one that trades people for mediocre software and then charges you to get the people back.
The pivot is capitulation born of economic desperation. While the productivity revolution has yet to properly arrive, enterprise adoption stalls and the lofty promises fail to materialize, AI companies are left hemorrhaging cash with no path to profitability in sight. Users grew impatient and investors grew restless. The quarterly reports told an increasingly grim story of spectacular costs, underwhelming revenue and a widening chasm between the hype and reality of what these systems could offer. Faced with this economic collapse, the industry has actually made a calculated retreat to safer ground. It has turned to the oldest form of engagement that there is: sex and emotional dependency. Not because it is innovative, but because it’s the last business model left that might actually work.
In another timeline, this technology might have been directed towards solving some of the hard problems of civilization, but instead we are wasting our advanced technology to simulate affection and desire. Sex sells, and our lonely, atomized society is buying.
End-Stage Enshittification Has Arrived
The enshittification of chatbots has completed the cycle:
Promise: A tool for augmenting knowledge
Adoption: A feature to save labor costs
Dependence: A mandatory interface for basic services
Extraction: A paywall to reach a real human being
Now, the product no longer serves its users; it feeds on them.
Exactly as Doctorow wrote:
“Platforms turn into businesses that eat their own users”
Welcome to Chatbot End-Stage Enshittification.
How we built a fully automated system that detects errors, suggests and applies fixes, and creates pull requests with zero human intervention
👀 Vision
Imagine a world where production errors are automatically detected, analyzed, and fixed without any human intervention. Where AI agents work together to maintain your codebase 24/7, creating pull requests that are automatically reviewed and deployed. This isn’t science fiction, it’s our reality.
We’ve built a complete automated AI bug fixing pipeline that transforms how we handle production errors. From the moment an error occurs to the final deployment, the entire process is handled by AI agents working in harmony.
🏠 Architecture Overview
Our pipeline consists of several interconnected components that work together seamlessly:
Datadog error monitoring
AWS API Gateway webhook with Lambda integration
Claude Code Fix Batch Job
Custom slack bot
Cursor slack bot
Github PR with auto review using Claude Code
Automated deployments
Let’s break down each component and see how they work together.
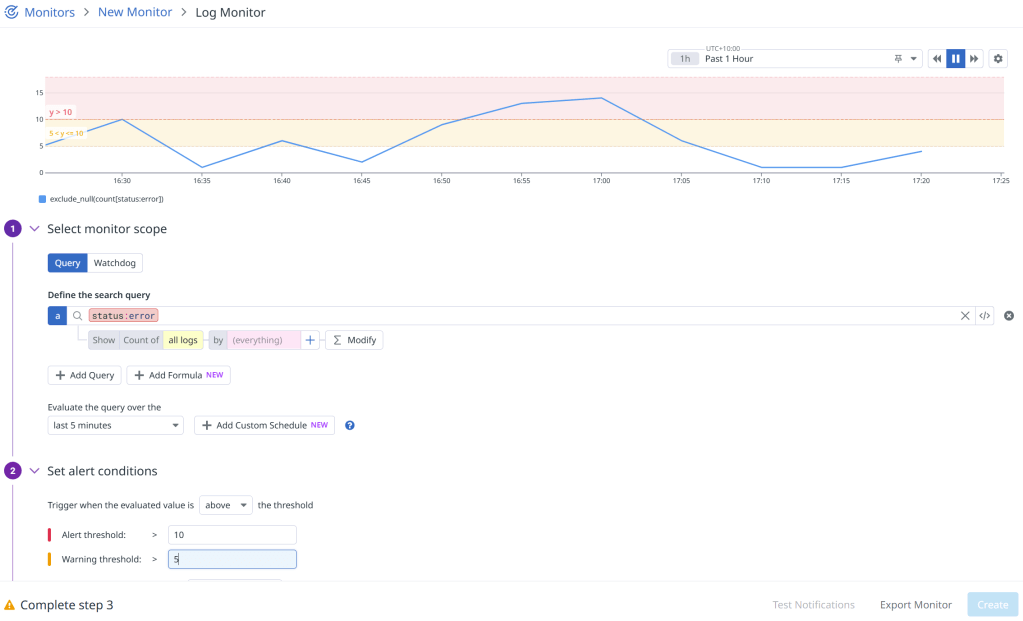
🐶 Step 1: Error Detection with Datadog
To begin, we have to configure Datadog monitors to watch for error patterns and trigger webhooks when thresholds are exceeded.
🎣 Webhook Integration
When an error threshold is exceeded, Datadog sends a webhook request to our API Gateway endpoint (using Lambda integration) with detailed error information.
Set up the webhook in Datadog by navigating to Integrations, search for “Webhook”, find “Webhooks by Datadog” and add a new webhook:
The URL here will be our API Gateway endpoint that will handle receiving and parsing the errors, then send them off to our batch job that will offer fix suggestions using Claude Code.
To use this webhook with our Datadog monitor, we simply add the name as a recipient to the template for the monitor we created earlier:
☁️ Step 2: Lambda Webhook Handler
Create a Lambda function to receive the webhook and process the error data. Attach the Lambda to an API Gateway so that it is accessible to Datadog:
public async Task<FunctionResponse> FunctionHandler(APIGatewayProxyRequest request, ILambdaContext context)
{
var requestId = Guid.NewGuid().ToString("N")[..8];
try
{
// Parse the webhook payload
var webhookData = System.Text.Json.JsonSerializer.Deserialize<JsonElement>(request.Body);
// Check if this alert should trigger a notification
var shouldNotify = await ShouldNotifySlack(webhookData, context, requestId);
if (shouldNotify)
{
// Send Slack notification and submit Claude Code Fix job
await SendSlackNotification(webhookData, context, requestId);
return new FunctionResponse
{
Success = true,
Message = "Slack notification sent successfully"
};
}
}
catch (Exception ex)
{
throw;
}
}
Error Data Retrieval from Datadog
The Lambda function doesn’t rely solely on the webhook payload. It actively fetches detailed error information from Datadog’s API to provide rich context for the AI analysis:
private async Task<List<ErrorLog>> FetchRecentErrorLogs(string query, int threshold, ILambdaContext context, string requestId)
{
try
{
var datadogApiKey = Environment.GetEnvironmentVariable("DATADOG_API_KEY");
var datadogAppKey = Environment.GetEnvironmentVariable("DATADOG_APP_KEY");
// Calculate time range (last 1 hour)
var endTime = DateTime.UtcNow;
var startTime = endTime.AddHours(-1);
// Use Datadog Logs API v2 to fetch detailed error logs
var requestBody = new
{
filter = new
{
query = query,
from = startTime.ToString("yyyy-MM-ddTHH:mm:ssZ"),
to = endTime.ToString("yyyy-MM-ddTHH:mm:ssZ")
},
sort = "timestamp",
page = new
{
limit = threshold
}
};
var json = System.Text.Json.JsonSerializer.Serialize(requestBody);
var content = new StringContent(json, Encoding.UTF8, "application/json");
using var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("DD-API-KEY", datadogApiKey);
httpClient.DefaultRequestHeaders.Add("DD-APPLICATION-KEY", datadogAppKey);
var response = await httpClient.PostAsync("https://api.datadoghq.com/api/v2/logs/events/search", content);
if (!response.IsSuccessStatusCode)
{
var errorContent = await response.Content.ReadAsStringAsync();
context.Logger.LogError($"[{requestId}] Datadog API error: {response.StatusCode} - {errorContent}");
return new List<ErrorLog>();
}
var responseContent = await response.Content.ReadAsStringAsync();
var logResponse = System.Text.Json.JsonSerializer.Deserialize<JsonElement>(responseContent);
var errorLogs = new List<ErrorLog>();
// Parse and enrich the error logs with additional context
if (logResponse.TryGetProperty("data", out var dataArray))
{
foreach (var log in dataArray.EnumerateArray())
{
var errorLog = new ErrorLog
{
Timestamp = ParseTimestamp(log),
Message = ExtractMessage(log),
Exception = ExtractException(log),
Url = ExtractUrl(log),
UserId = ExtractUserId(log),
TraceId = ExtractTraceId(log)
};
errorLogs.Add(errorLog);
}
}
return errorLogs;
}
catch (Exception ex)
{
return new List<ErrorLog>();
}
}
This data enrichment process provides the AI with more context than what’s available in the webhook payload alone, including:
Full error stack traces with line numbers and file paths
Request context including URLs, user IDs, and trace IDs
Timing information for error frequency analysis
Environment details and service information
Custom metadata from your application logs
Error Analysis and Grouping
The Lambda function doesn’t just forward the error, it analyzes and groups similar errors to avoid spam:
For each unique error, our Lambda webhook handler will submit a batch job to our ClaudeCodeFixJob. This job clones the repository, installs Claude Code, and generates fix suggestions.
Batch Job Submission
private async Task SubmitClaudeFixJob(UniqueError uniqueError, JsonElement webhookEvent, ILambdaContext context, string requestId)
{
var environment = Environment.GetEnvironmentVariable("ENVIRONMENT") ?? "unknown";
var jobDefinitionName = $"{environment}-ClaudeCodeFixJob";
var jobQueueName = $"{environment}-claude-fix-queue";
// Create error data for the batch job
var errorData = new
{
ErrorType = ExtractErrorType(uniqueError.Exception),
ErrorMessage = uniqueError.ErrorMessage,
Component = "API",
Service = "MyAPI",
Timestamp = DateTime.UtcNow.ToString("yyyy-MM-dd HH:mm:ss UTC"),
Environment = environment,
AdditionalData = new Dictionary<string, object>
{
["occurrenceCount"] = uniqueError.OccurrenceCount,
["firstOccurrence"] = uniqueError.FirstOccurrence.ToString("yyyy-MM-dd HH:mm:ss UTC"),
["lastOccurrence"] = uniqueError.LastOccurrence.ToString("yyyy-MM-dd HH:mm:ss UTC"),
["sampleUrls"] = uniqueError.SampleUrls,
["sampleUserIds"] = uniqueError.SampleUserIds,
["sampleTraceIds"] = uniqueError.SampleTraceIds
}
};
// Submit the batch job
var submitJobRequest = new SubmitJobRequest
{
JobName = $"claude-fix-{DateTime.UtcNow:yyyyMMdd-HHmmss}-{uniqueError.ErrorMessage.GetHashCode()}",
JobQueue = jobQueueName,
JobDefinition = jobDefinitionName,
ContainerOverrides = new ContainerOverrides
{
Environment = environmentVariables
}
};
var submitJobResponse = await _batchClient.SubmitJobAsync(submitJobRequest);
}
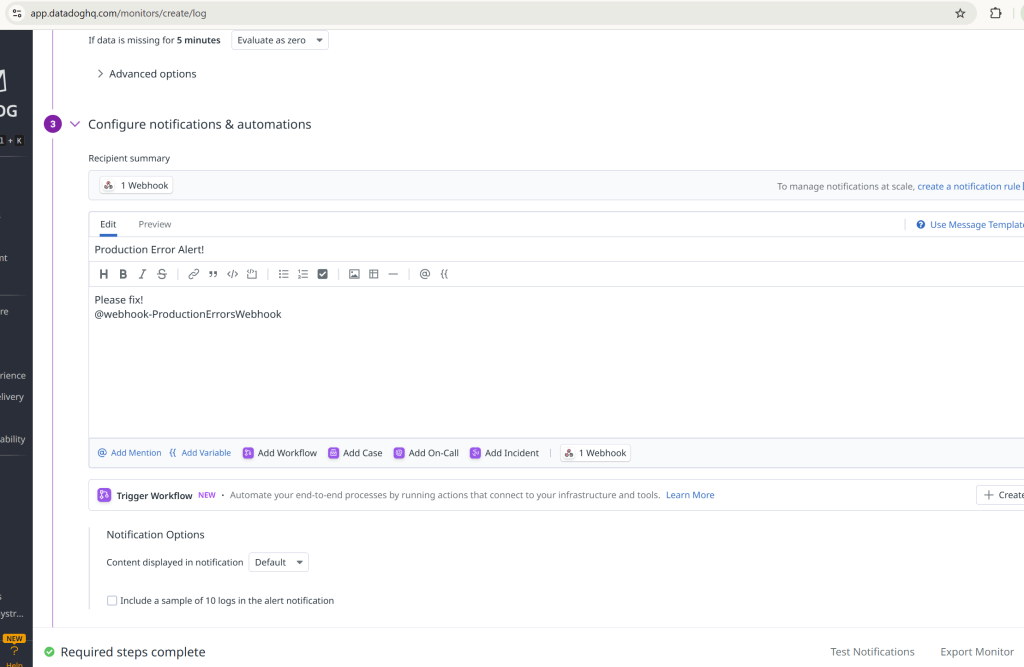
🤖 Step 4: Slack Bot Integration
Creating the Slack Bot
First, we create a Slack app in the Slack API dashboard:
The bot needs specific permissions to send messages and interact with channels:
# Required OAuth Scopes for the bot
scopes:
- chat:write # Send messages to channels
- chat:write.public # Send messages to public channels
- channels:read # Read channel information
- users:read # Read user information
- app_mentions:read # Read mentions of the bot
⚙️ Step 5: Batch Job Setup
The batch job uses Claude Code to analyze the error and generate fix suggestions.
Repository Cloning and Setup
Before Claude Code can analyze the codebase, we need to clone the repository and set up the environment:
private string? CloneRepository()
{
try
{
var repoPath = Path.Combine(_workingDirectory, "repo");
if (Directory.Exists(repoPath))
{
using var repo = new Repository(repoPath);
// Configure git credentials for private repositories
if (!string.IsNullOrEmpty(_githubToken))
{
var signature = new Signature("Claude Fix Bot", "claude@company.com", DateTimeOffset.Now);
var options = new PullOptions
{
FetchOptions = new FetchOptions
{
CredentialsProvider = (_url, _user, _cred) =>
new UsernamePasswordCredentials
{
Username = "token",
Password = _githubToken
}
}
};
Commands.Pull(repo, signature, new PullOptions());
}
else
{
Commands.Pull(repo, new Signature("Claude Fix Bot", "claude@company.com", DateTimeOffset.Now), new PullOptions());
}
}
else
{
var cloneOptions = new CloneOptions
{
BranchName = _gitBranch,
Checkout = true
};
// Add credentials for private repositories
if (!string.IsNullOrEmpty(_githubToken))
{
cloneOptions.CredentialsProvider = (_url, _user, _cred) =>
new UsernamePasswordCredentials
{
Username = "token",
Password = _githubToken
};
}
Repository.Clone(_gitRepoUrl, repoPath, cloneOptions);
}
// Verify the repository was cloned/updated correctly
using var repo = new Repository(repoPath);
var currentBranch = repo.Head.FriendlyName;
var lastCommit = repo.Head.Tip;
return repoPath;
}
catch (Exception ex)
{
return null;
}
}
Claude Code Installation
Once the repository is cloned, we install and configure Claude Code:
private async Task<bool> InstallClaudeCodeAsync(string repoPath)
{
try
{
// Check if Node.js is available
var nodeResult = await ExecuteCommandAsync("node", "--version", repoPath);
if (nodeResult.ExitCode != 0)
{
return false;
}
// Install Claude Code globally
var installResult = await ExecuteCommandAsync("npm", "install -g @anthropic-ai/claude-code", repoPath);
if (installResult.ExitCode != 0)
{
return false;
}
// Update Claude Code to latest version
var updateResult = await ExecuteCommandAsync("claude", "update", repoPath);
if (updateResult.ExitCode != 0)
{
// Continue anyway, the installed version might work
}
// Configure Claude Code authentication
var anthropicApiKey = Environment.GetEnvironmentVariable("ANTHROPIC_API_KEY");
if (!string.IsNullOrEmpty(anthropicApiKey))
{
// Set the API key for Claude Code
var configResult = await ExecuteCommandAsync("claude", $"config set api_key {anthropicApiKey}", repoPath);
}
}
catch (Exception ex)
{
return false;
}
}
Command Execution Helper
We use a robust command execution helper for all CLI operations:
private async Task<(int ExitCode, string Output, string Error)> ExecuteCommandAsync(
string command,
string arguments,
string workingDirectory,
int timeoutSeconds = 60)
{
try
{
var startInfo = new System.Diagnostics.ProcessStartInfo
{
FileName = command,
Arguments = arguments,
WorkingDirectory = workingDirectory,
RedirectStandardOutput = true,
RedirectStandardError = true,
UseShellExecute = false,
CreateNoWindow = true
};
using var process = new System.Diagnostics.Process { StartInfo = startInfo };
process.Start();
// Use a timeout to prevent hanging processes
var outputTask = process.StandardOutput.ReadToEndAsync();
var errorTask = process.StandardError.ReadToEndAsync();
var exitTask = process.WaitForExitAsync();
// Wait for all tasks with timeout
var timeoutTask = Task.Delay(TimeSpan.FromSeconds(timeoutSeconds));
var completedTask = await Task.WhenAny(exitTask, timeoutTask);
if (completedTask == timeoutTask)
{
// Timeout occurred
try
{
process.Kill();
}
catch { }
return (-1, "", $"Command timed out after {timeoutSeconds} seconds");
}
var output = await outputTask;
var error = await errorTask;
return (process.ExitCode, output, error);
}
catch (Exception ex)
{
return (-1, "", ex.Message);
}
}
Claude Code Integration
Once the repository is cloned and Claude Code is installed, we can analyze errors:
private async Task<string?> GetClaudeFixSuggestionAsync(string repoPath, ErrorFixRequest errorData)
{
try
{
// Clean and prepare the error message
var cleanErrorMessage = errorData.ErrorMessage;
var parts = cleanErrorMessage.Split("info error:");
if (parts.Length > 1)
{
cleanErrorMessage = parts[1].Trim();
}
// Create the prompt for Claude Code
var simplePrompt = _claudePromptTemplate
.Replace("{ErrorType}", errorData.ErrorType)
.Replace("{ErrorMessage}", cleanErrorMessage)
.Replace("{Component}", errorData.Component)
.Replace("{Service}", errorData.Service)
.Replace("\\n", "\n");
// For command line safety, replace newlines with spaces
var commandLinePrompt = simplePrompt.Replace("\n", " ");
// Run Claude Code with the repository context
var result = await ExecuteCommandAsync("claude", $"-p \"{commandLinePrompt}\"", repoPath, 600);
if (result.ExitCode != 0)
{
return "Failed to get response from Claude Code - the tool may not be working in this environment";
}
// Check if we got any output
if (string.IsNullOrEmpty(result.Output))
{
return "No response received from Claude Code - the command may have failed or timed out";
}
// Extract the response from the output
var response = ExtractClaudeResponse(result.Output);
return response;
}
catch (Exception ex)
{
return null;
}
}
Send Slack Message
private async Task SendSlackMessageAsync(string message)
{
var payload = new
{
channel = _slackChannel,
text = message,
username = "Claude Code Fix Bot",
icon_emoji = ":robot_face:"
};
var json = JsonConvert.SerializeObject(payload);
var content = new StringContent(json, Encoding.UTF8, "application/json");
using var httpClient = new HttpClient();
var response = await httpClient.PostAsync(_slackWebhookUrl, content);
}
Example Slack Message
The bot sends structured messages like this:
🤖 Claude Code Fix Suggestion
Error Details:
• Type: NullReferenceException
• Message: Object reference not set to an instance of an object
• Component: UserService
• Service: API
🐛 Claude's Suggested Fix:
```
// Add null check before accessing user object
if (user != null)
{
return user.Name;
}
return "Unknown User";
```
👉 Next Steps:
Review the suggestion above and reply to this message tagging @cursor to apply the changes.
🔈 Step 6: Cursor Bot Integration
You can find the Cursor Slack bot here. Install it to your workspace and configure it.
When a team member reviews the suggestion and wants to apply the change, they simply reply to the Slack message tagging @cursor. Cursor then:
Analyzes the error and suggested fix
Creates a new branch with the changes
Commits the fix
Creates a pull request
✏️ Step 7: Automated Code Review
When a pull request is created, our GitHub Action automatically triggers a code review using Claude:
name: Claude Code Review
on:
pull_request:
types: [opened]
jobs:
claude-review:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
issues: write
id-token: write
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
fetch-depth: 1
- name: Notify Slack - Review Started
uses: 8398a7/action-slack@v3
with:
status: custom
custom_payload: |
{
"attachments": [{
"color": "#FFA500",
"text": "🤖 Claude is *STARTING* code review for ${{ github.repository }}\n• *PR:* #${{ github.event.pull_request.number }} - ${{ github.event.pull_request.title }}\n• *Author:* ${{ github.event.pull_request.user.login }}"
}]
}
env:
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
- name: Run Claude Code Review
uses: anthropics/claude-code-action@beta
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
github_token: ${{ github.token }}
direct_prompt: |
Please review this pull request and provide feedback on:
- Code quality and best practices
- Potential bugs or issues
- Performance considerations
- Security concerns
- Test coverage
Be constructive and helpful in your feedback.
🚀 Step 8: Auto-Deployment
Once the pull request is approved and merged, our existing CI/CD pipeline automatically deploys the changes to our desired environment.
➕Results and Benefits
Before the Pipeline:
Error Detection: Manual monitoring required
Error Analysis: Developers had to investigate each error
Fix Creation: Manual code changes and testing
Deployment: Manual review and deployment process
Time to Resolution: Hours to days
After the Pipeline:
Error Detection: Automatic via Datadog
Error Analysis: AI-powered analysis with Claude Code
Fix Creation: Automated suggestions and code changes
Deployment: Fully automated with AI review
Time to Resolution: Minutes to hours
Example Result
This output was based on a dummy API endpoint that logs errors in order to test the pipeline. It correctly detected that the endpoint was a dummy and suggested to remove it, which was then applied to the codebase with a PR from Cursor. This PR was then automatically reviewed by Claude Code, checked by a human and automatically deployed. The only human intervention was to apply the suggestion and look at PR and associated AI code review!
👉 What’s Next?
Multi-Language Support: Extend to Python, Javascript, Go
Advanced Error Classification: Use Machine Learning to categorize errors more accurately
Rollback Automation: Automatic rollback if fixes cause new errors
Performance Monitoring: Track fix effectiveness and performance impact
Team Notifications: Escalate to human developers for complex issues
JIRA Integration: Handle human and user submitted errors
Technical Debt Detection: Scheduled job to detect technical debt and offer suggestions to address
The future of DevOps is AI-automated, and it’s already here
The Agile software development process began as a manifesto, a welcome change from the stifling hierarchies and waterfall workflows of traditional project management. It was a revolutionary ethos — prioritizing team collaboration, fast responses to change, early feedback, and the promise of better ways of working. Agile promised liberation — from bureaucratic stagnation, from rigid planning, and from the tyranny of predictability in an unpredictable world. It was supposed to be about adaptability, trust, and respect for the intricate art of creation.
But revolutions have a way of eating their young.
Today, Agile resembles less a path to freedom and more a prison of our own making. Stand-ups devolve into surveillance sessions, sprint planning into a charade of false precision, and status updates into a theater of productivity for its own sake. Unmanageable backlogs grow ever larger, while the methodology, wielded by business stakeholders, serves primarily to further commodify time — leaving teams with a far less enjoyable and fulfilling experience.
Clocked In: How Agile Turned Time Into Currency
In the world of Agile, time — the most scarce and therefore valuable resource we have — is now sliced into “story points” and “velocity metrics,” flattened into graphs and charts, packaged and sold as a deliverable. What began as a tool to enhance creativity has evolved into a machinery of control, where every second is scrutinized, every action accountable, and every estimate a binding contract.
Nowhere is this more evident than in the obsession with “timeboxing.” The Agile sprint, once a simple mechanism for focusing effort, has become the rhythm of an unyielding metronome. Developers are expected to predict the unpredictable, to break the vast unknown into bite-sized certainties. This relentless commodification of time, pushed by business stakeholders often far removed from the technical complexities, transforms innovation into an assembly line of estimates, deadlines, and deliverables. The inevitable chaos of creative work is treated not as an intrinsic feature, but as a defect to be eradicated.
The tragedy of Agile’s fall is not only its failure to deliver on its promise, but the way in which it has subtly reshaped how we think about work itself. Time is no longer a medium for exploration, invention, or growth; it is a currency, measured in points, burned down to zero, and audited like a ledger. Agile, the revolution, has become Agile, the system — and in doing so, it has turned time itself into a commodity.
Time as Labor: The Industrial Revolution’s Legacy
The commodification of time has its roots in the Industrial Revolution, when the rhythm of work shifted from the natural cadence of tasks to the relentless tick of the clock. Before this era, labor was largely task-oriented — farmers worked from sunrise to sunset, craftsmen toiled until their projects were complete, and time was a fluid backdrop to human activity. The advent of factories changed everything. It was the capitalists, the ruling class, the managers, and the bosses who introduced clocks into the work environment, not as neutral tools but as instruments of control. Clocks became the ultimate arbiters of productivity, dictating when workers started, stopped, and how long they could rest. Under their watchful gaze, time ceased to be an abstract measure of human experience and was transformed into a commodity — tightly regulated, monetized, and intimately tied to output, all for the benefit of those who owned the means of production.
This shift marked the birth of “time as money”, an ethos that persists today. Employers no longer paid for what was accomplished but for the hours spent on the factory floor. This transformation, while revolutionary in its efficiency, redefined human labor as something to be sliced into measurable, sellable units. The worker’s value was reduced to their ability to meet the clock’s demands, creating a system that prized uniformity and predictability over creativity and individuality.
The echoes of this transformation are still felt in modern workplaces, where time is tracked, optimized, reported on and monetized with ever-increasing precision. Agile’s obsession with timeboxes and velocity metrics, though couched in the language of collaboration, is an extension of this industrial logic. Just as factory managers sought to maximize output per hour, today’s stakeholders seek to extract maximum value from every sprint. What was once a tool of liberation risks becoming yet another tool of control, binding workers to the clock under the guise of innovation.
Business vs. Technical Realities
The tension between business imperatives and technical realities lies at the heart of Agile’s most pressing challenges. On one side, business stakeholders demand clarity, predictability, and speed — outcomes that can be packaged into neatly defined milestones and delivered on time. On the other side, developers wrestle with complexity, ambiguity, and the iterative nature of solving problems in uncharted terrain. These two worlds, though deeply interconnected, often speak entirely different languages, and Agile, intended as a bridge, has instead become a battlefield.
For business stakeholders, Agile offers the seductive promise of control. Through sprints, story points, and charts, they gain a window into the development process, and a way to measure progress and hold teams accountable. Yet this perspective often oversimplifies the messy, emergent nature of technical work. Software development is not manufacturing; it cannot be reduced to a production line where inputs reliably yield outputs. Bugs, unforeseen dependencies, and the sheer creativity required to solve complex problems defy the rigid frameworks of business planning.
Developers face the impossible task of reconciling the demand for predictability with the inherently unpredictable nature of their labor. Estimates become commitments, even when they are little more than educated guesses. Teams are pressured to deliver on time, even as the scope of work evolves mid-sprint or unforeseen challenges arise. The result is a process that rewards short-term compromises — cutting corners, taking on technical debt — over long-term quality and innovation. What should be a collaborative partnership between business and technical teams too often devolves into a cycle of frustration and blame.
This misalignment is exacerbated by the differing incentives of the two groups. For business leaders, success is measured by deadlines met, budgets adhered to, and deliverables shipped. For developers, success lies in creating elegant, sustainable solutions that stand the test of time. Agile, at its best, is meant to harmonize these priorities, fostering transparency and collaboration. But in practice, it often magnifies the conflict, forcing developers to sacrifice their craft on the altar of business metrics. The more we strive to force these two worlds into alignment, the more their fundamental incompatibility becomes apparent, exposing deeper flaws in how we define and measure success in modern work.
The path forward must lie in reframing the relationship between business and technical teams. Instead of treating time as the ultimate metric of value, stakeholders must embrace the realities of exploration and uncertainty inherent in creative work. This means shifting the focus from rigid schedules to outcomes, prioritizing quality over quantity, and valuing the expertise of the technical team as much as the goals of the business. Agile, in its original intent, was never about domination by either side. It was about partnership — and we must reclaim that spirit before the gap grows too vast to close.
Creativity and Human Flourishing Under Siege
At its essence, creative work thrives on freedom — the freedom to explore uncharted ideas, to take risks, and to fail without fear of retribution. Yet in the modern workplace, particularly within the frameworks imposed by Agile and other time-bound methodologies, this freedom is increasingly under attack. The relentless drive for efficiency, accountability, and output reduces creativity to a constrained process, one that must fit within predefined structures and deliver results on a tightly controlled schedule. In this environment, the deeper elements of human flourishing — curiosity, inspiration, and the joy of creation — are often the first casualties.
The commodification of time is at the heart of this issue. When every hour is scrutinized, measured, and monetized, the very nature of creative work is fundamentally altered. True creativity rarely unfolds neatly within a two-week sprint or conforms to the confines of a backlog. It requires space for serendipity, for following unanticipated threads of thought, and for allowing ideas to marinate. Yet under the modern obsession with velocity and deliverables, this space is increasingly viewed as wasteful or inefficient.
This pressure erodes not only the quality of work but also the morale of those creating it. Developers, designers, and other creative professionals are caught in an endless cycle of sprint deadlines, constant status updates, and the looming specter of charts that reduce their efforts to numbers on a graph. The result is a widespread sense of disconnection, as individuals feel their creativity is being subordinated to the mechanical churn of production. Inevitably, what was once a source of passion and fulfillment becomes another cog in the machine.
Beyond the personal toll, this shift has broader implications for innovation. The most transformative ideas often emerge not from rigid processes but from organic, unstructured moments of creativity. Yet in today’s Agile landscape, even time for innovation must be pre-defined and meticulously accounted for, as seen in concepts like “20% time.” While such initiatives aim to carve out space for creativity, they paradoxically constrain it by formalizing what should arise naturally. This approach turns the spontaneous nature of innovation into another scheduled deliverable, stripping it of the freedom to emerge organically — as most great ideas do. Agile was supposed to empower teams to adapt, iterate, and innovate, but as it exists today, it often achieves the opposite — stifling the very experimentation it was designed to foster. The relentless focus on short-term deliverables leaves little room for the kind of bold, long-term thinking that leads to meaningful breakthroughs.
Reclaiming creativity in the workplace requires a cultural shift. Organizations must move away from treating time as a commodity and toward valuing the intrinsic unpredictability of creative work. This means granting teams the autonomy to explore without constant oversight, redefining success to include intangible outcomes like learning and inspiration, and fostering an environment where risk-taking is not just tolerated but encouraged.
Ultimately, the heart of this issue lies in how we view work itself. If work is reduced to mere output — a series of transactions to be optimized and monetized, the assault on creativity will persist. But if work is recognized as a vital part of human flourishing — a space for self-expression, growth, and the realization of ideas — then there is hope for a future where creativity is not only preserved but celebrated. It is this perspective that allows the most creative, innovative, and meaningful inventions to emerge. It is not enough to carve out pockets for creativity within the existing system; the system itself must be reimagined to prioritize the flourishing of the people who power it.
Agile and the Machinery of Late-Stage Capitalism
At its core, late-stage capitalism is defined by the relentless pursuit of efficiency, profit, and control — often at the expense of the very humans who fuel its engines. Agile, in its commodified form, has become a fitting metaphor for this system, a tool once designed to empower creativity now repurposed to extract maximum value from every minute of labor. In the hands of late-stage capitalism, Agile serves not as a framework for innovation but as a mechanism for optimizing output and minimizing costs, all while cloaking its demands in the language of collaboration and flexibility.
The commodification of time is central to this dynamic. Late-stage capitalism thrives on the ability to quantify and monetize every aspect of human activity, reducing work to a series of inputs and outputs. Late-stage Agile, as it exists today, fits snugly into this paradigm, transforming the unpredictable nature of creative work into a spreadsheet of measurable deliverables. But this obsession with metrics overlooks the intrinsic value of exploration, experimentation, and the ineffable magic of creativity — elements that cannot be neatly captured in a sprint report or chart.
Mark Fisher’s observation in Capitalist Realism rings hauntingly true:
“It’s easier to imagine the end of the world than the end of capitalism.”
Agile, in its distorted and commodified state, embodies this sentiment. Originally conceived as a framework to empower creativity and adaptability, it has been co-opted by the very system it sought to navigate, transformed into yet another mechanism for extraction and perpetual growth. Its ideals of collaboration and innovation have been twisted to meet the relentless demands of a system obsessed with efficiency and profit. Rather than freeing teams to explore the possible, Agile has become a tool for enforcing the relentless churn of deliverables, perpetuating the belief that there is no alternative to this mode of production.
This is capitalism’s insidious strength — its ability to capture, repurpose, and commodify anything, even systems that offer alternatives to its logic. Fisher’s quote speaks directly to this phenomenon: capitalism’s dominance is so pervasive, so entrenched, that it reshapes even well-meaning frameworks into reflections of itself. Agile, once a framework aimed at fostering adaptability and collaboration, has been subsumed by this system. It is now wielded as a tool of control, transforming the boundless possibilities of creativity into measurable outputs and reducing human ingenuity to commodified increments of time and labor.
Even our aspirations are not safe from this capture. Innovation, collaboration, and flexibility — the core values of Agile — are subsumed under the relentless logic of profit and efficiency, transformed into buzzwords that drive shareholder value rather than human flourishing. In this way, capitalism ensures its perpetuation, not by suppressing alternatives, but by absorbing them, reshaping them until they reinforce the very systems they were meant to undermine. Agile, in its late-stage form, reflects this tragic inevitability, standing as both a product of and testament to capitalism’s all-consuming reach.
The parallels run deeper still. Late-stage capitalism thrives on perpetual growth, an endless cycle of scaling, iterating, and extracting. Agile, in its current incarnation, mirrors this logic. The focus is not on creating something truly great but on delivering something quickly, moving on to the next sprint, the next iteration, then the next project. Quality is often sacrificed for speed, and long-term sustainability is overshadowed by short-term gains. This drive for continuous output transforms Agile teams into factories of deliverables, reinforcing the very conditions Agile was designed to disrupt.
Agile, as practiced under late-stage capitalism, amplifies the power imbalance between business stakeholders and creative professionals. It prioritizes the needs of shareholders and managers over the well-being of the teams doing the work. Developers, designers, and other creators are forced to justify their every move, to account for every hour spent, and to perform their labor within increasingly narrow constraints. This dynamic reflects the broader exploitation inherent in late-stage capitalism, where workers are valued only insofar as they contribute to the bottom line.
The broader societal impact is equally troubling. By normalizing the commodification of time and creativity, Agile reinforces a cultural narrative that views humans as resources to be optimized rather than beings capable of growth, inspiration, and profound innovation. It perpetuates a system where work is stripped of its joy and meaning, reduced to a transactional exchange in service of capital.
To break this cycle, we must reimagine Agile as a counterbalance to the excesses of late-stage capitalism rather than an instrument of its machinery. Agile, in its original intent, was about people over processes, collaboration over contracts, and adaptability over rigid plans. By reclaiming these principles, we can transform Agile from a tool of exploitation into one of empowerment, one that prioritizes human flourishing over mere productivity.
This reimagining is not just about improving the workplace; it is about challenging the broader systems that commodify our lives. It is about recognizing that creativity, time, and human effort are not infinite resources to be consumed but precious elements to be nurtured and respected. In pushing back against the distortions of late-stage capitalism, we reclaim not only the spirit of Agile but the dignity of work itself.
A Call to Reclaim the Original Spirit of Agile
To reclaim the original spirit of Agile, we must first confront how far we’ve drifted from its founding principles. Agile was never meant to be a straitjacket of stand-ups, sprints, and velocity metrics. It was a philosophy, not a prescription. Yet today, teams are often forced into rigid rituals that prioritize output over outcomes, deadlines over discovery, and efficiency over excellence. The result is a system that serves the illusion of control rather than the reality of innovation.
The heart of Agile lies in its emphasis on collaboration and trust. It calls for open communication between stakeholders and teams, for the recognition that creative work is inherently unpredictable, and for a willingness to embrace uncertainty as a fertile ground for innovation. Reclaiming this spirit means moving beyond the mechanical application of Agile frameworks and returning to its humanistic roots.
This begins with restoring autonomy to teams. Trusting professionals to manage their time and creativity is not a risk; it is a necessity. Agile must empower teams to experiment, explore, and iterate without the relentless pressure of rigid deadlines and metrics. True collaboration emerges not from micromanagement but from mutual respect and a shared commitment to the work itself.
Reclaiming Agile also requires redefining success. It’s not about story points or hitting sprint goals; it’s about delivering value in a way that respects the complexities of creative work. This means valuing quality over speed, outcomes over optics, and adaptability over adherence to process. For agile to once again flourish, it must reclaim it’s place as a tool for navigating uncertainty, not a weapon for enforcing predictability.
Finally, we must remember that Agile was designed for humans, not machines. It is not about squeezing every last drop of productivity from a team but about creating an environment where people can do their best work. This means fostering creativity, encouraging risk-taking, and making space for the kind of deep thinking that leads to true innovation. The original Agile manifesto was a celebration of humanity in the workplace, and it is time to return to that vision.
The Agile revolution began with a simple idea — that people, empowered and trusted, could accomplish extraordinary things. That spirit still exists, waiting to be revived. By stripping away the layers of commodification and control, we can once again make Agile a force for creativity, collaboration, and human flourishing.
Artificial intelligence is celebrated as a transformative force poised to reshape the fabric of human existence. Yet, lurking beneath this polished and curated narrative is a disturbing reality, where the very systems lauded for their ingenuity are underpinned by a hidden lattice of exploitation. In their pursuit of a “safer”, more sophisticated AI, tech companies have outsourced the most harrowing tasks to low paid contractors forced to confront humanity’s darkest content.
For example, in Kenya, workers earning between $1.32 to $2 an hour have been tasked with labeling grotesque depictions of violence, sexual abuse, and other horrors to train AI models such as ChatGPT. Partnering with the outsourcing firm Sama, OpenAI relied on these individuals to engineer safeguards against harmful content. This labor has extracted a severe human toll — inadequate pay, poor mental health support, in a work environment as exploitative as it is dehumanizing.
This is certainly not an isolated case but emblematic of a systemic problem in the AI industry — a space where profits are underwritten by the silent suffering of unseen laborers.
The question is not just how we build AI, but at what cost — and who bears the weight of its creation?
From Moderation To Training
The exploitation of labor for content moderation can be seen as the first phase in a broader strategy that has now extended to AI training. Content moderation established a playbook — outsourcing emotionally grueling tasks to underpaid workers shielded from the public view. These workers, who are often contracted through third-party firms, labor under tightly controlled conditions, processing graphic and harmful content for the sake of platform safety. This model not only addressed the immediate needs of moderating user-generated content but also normalized a system in which the most unpleasant and critical tasks in tech could be quietly outsourced to vulnerable workers.
This approach has since been replicated in the AI industry, where data labeling jobs mirror the structure and demands of content moderation. Just as moderators sift through posts to uphold community standards, data labelers comb through massive datasets, tagging images, text, and videos — including incredibly disturbing material — to train AI systems. Both roles demand high productivity under suffocatingly intense surveillance while offering inadequate pay and minimal mental health support. The precedent set by content moderation has effectively paved the way for the same labor exploitation practices to proliferate in AI development, raising urgent questions about the human cost of technological progress.
Controversial Companies and Practices
The companies leading AI development have faced mounting criticism for their reliance on exploitative labor practices. Cognizant, Appen, Sama, and others have become emblematic of a new form of global outsourcing. These firms hire contractors to sift through sensitive or explicit material under the guise of building safer, smarter AI systems. While the tech giants funding these efforts — OpenAI, Meta, and Google, among others — enjoy their enormous profits, the workers powering this ecosystem are trapped in a precarious existence. Companies like Cognizant, Appen, and Sama call themselves AI companies, but it would be more accurate to describe them as “labor exploitation companies.”
Scandals have further exposed these inequities. Cognizant, for instance, faced backlash after reports revealed its content moderators often processed hundreds of posts daily — up to 400 in some cases — with less than 30 seconds per item and minimal support. Sama, which helped train OpenAI’s ChatGPT, came under scrutiny for paying Kenyan workers wages that barely exceeded the local minimum and offering little relief from the mental strain of their assignments.
Appen, a prominent AI data services company, has faced significant controversies that underscore the ethical challenges within the industry. In the beginning of 2024, Appen lost major clients, including Google, Amazon, Facebook, and Microsoft, which accounted for over 60% of its revenue. This decline was attributed to concerns over the quality of services and treatment of contractors. Contractors have accused Appen of enforcing unreasonable deadlines, delaying payments, exhibiting alleged racism in its recruitment processes, and maintaining poor working conditions for those handling AI datasets. These issues have sparked widespread criticism and raised serious questions about the company’s labor practices. They underscore the ethical dilemmas in the AI industry, where the relentless pursuit of innovation frequently eclipses the well-being of the human workforce that sustains it.
Displacing Jobs for Profit
The irony of AI’s rise is that the very labor used to build these systems is being targeted for obsolescence. Many AI developers openly aim to replace human jobs with automated solutions, driven by a relentless pursuit of profit. From customer service agents to legal analysts, the goal is to make human workers redundant while maximizing efficiency. Yet, little consideration is given to the lives disrupted in the process or the structural inequities that automation exacerbates.
AI advocates often compare this shift to the industrial revolution or the advent of the printing press, framing it as a natural and inevitable progression. But such comparisons overlook the darker realities and social costs of these historical transformations. The printing press, for all its contributions to knowledge dissemination, also gave rise to propaganda machines capable of stoking division and fueling world wars. Similarly, the industrial revolution was marked by harsh working conditions, child labor, and exploitative practices that persisted for decades before reforms took hold. These changes were not unmitigated blessings, and the same is true of AI’s rise. Without careful oversight, the pursuit of progress risks not only repeating but also amplifying the exploitation and inequities of the past, all while paving the way for new harms to emerge.
The profit motive that drives AI companies prioritizes cost-cutting and scalability over any ethical considerations. As companies accelerate their push for automation, they create an unsettling paradox — relying on exploited labor to build systems designed to erase the need for labor altogether. The hollow rhetoric of “progress” becomes difficult to reconcile with the reality of displaced workers and communities left without viable alternatives.
Towards Ethical AI
The story of AI is not just one of innovation but also one of exploitation and inequality. The workers who train these systems are erased from the narrative, with their contributions hidden behind abstractions like “machine learning” and “automation.” Meanwhile, the march toward replacing human jobs with AI systems proceeds unabated, deepening economic divides.
If artificial intelligence is to truly serve humanity, it cannot be built on the backs of exploited workers. The industry must confront its ethical responsibilities — fair wages, mental health protections, and a commitment to creating — not destroying — opportunities for meaningful work. Technology can be a force for good, but only if it values the humanity of those who power it. The question we must ask is not what these systems can do but who they truly serve.
The term “Artificial General Intelligence” (AGI) has long been a source of fascination, speculation, and confusion. It conjures visions of machines capable of thinking, reasoning, and acting like humans across a wide range of tasks. As this current AI hype cycle has accelerated, companies have begun making grand claims about how close they are to this mythical AGI, purporting that achieving it is just around the corner. Beneath this hyperbolic rhetoric lies an inconvenient truth: AGI, as marketed today, is more of a gimmick than a genuine scientific pursuit.
What Are They Really Selling?
Marketing gimmicks are nothing new in the tech industry, but few have been as seductive as the promise of AGI. It holds out the tantalizing prospect of machines not merely excelling in narrow tasks but demonstrating understanding and competence across multiple domains — potentially surpassing human capabilities. However, the companies invoking AGI often appear less interested in unraveling the mysteries of human intelligence than in selling snake oil. They leverage the term to secure funding or inflate stock prices, prioritizing short-term gains over meaningful progress.
The so-called “AGI” systems being built today are, in reality, glorified statistical models — massive neural networks trained on vast datasets in order to give the illusion of intelligence. The prevailing narrative suggests that simply scaling these networks will lead to general intelligence. This overlooks fundamental constraints, such as the diminishing returns of scaling and the likelihood of hitting a technological plateau. This concept is counter-intuitive to many as they believe in “exponential improvements”, yet in reality this is not how it works; technology often reaches a plateau due to the complexity of solving the last 1%. What is further counter-intuitive is that the last 1% can actually take exponentially longer than the first 99% to solve, and in many cases that means that productionizing technology for certain use cases never actually comes to fruition, or the cost to get there is too great and not worthwhile. In some cases, this final 1% may represent the leap required to achieve AGI — or it may be an even more daunting problem than acknowledged.
A core limitation of today’s systems is their inability to comprehend the concepts they process. These models excel at pattern recognition and interpolation but lack true understanding. They cannot abstract knowledge and apply it to novel situations, a hallmark of general intelligence. Instead, they process data with brute computational force, devoid of the insight needed to navigate unfamiliar contexts.
The Limits of A Neural-Only Approach
At the heart of this AGI hype lies an overreliance neural networks, loosely inspired by the structure of the human brain. While neural networks have achieved remarkable success in narrow domains, they face fundamental challenges in achieving general intelligence.
Neural networks are adept at processing large datasets but struggle with abstract reasoning, symbolic manipulation, and understanding relationships between concepts. They represent objects and attributes as vectors — multi-dimensional data structures that encode numerical values to form conceptual representations. Yet, these systems merely map inputs to outputs without goals, motivations, or self-reflection.
A true AGI should be capable of autonomously abstracting its findings across multiple layers to construct a multi-faceted understanding of both objects and their relationships within a complex, ever-changing environment. It should be able to adapt its knowledge dynamically, discerning when to apply or withhold it based on changes in its surroundings.
Scaling neural networks alone will not address these limitations; instead, it often amplifies inefficiencies and environmental costs.
The Case for Neuro-Symbolic AI
In order to move beyond this shallow imitation of intelligence, we must first embrace a neuro-symbolic approach; a combination of neural networks with symbolic reasoning systems. Both of these systems work well together since a neural network can excel at perception, pattern recognition and processing of unstructured data, while symbolic systems can handle and model abstract reasoning, logical deduction and manipulate concepts and relationships.
For instance, in image processing, a neural network might identify an object in an image, while a symbolic layer reasons about its properties and relationships to other objects. This layered approach mirrors how humans combine intuition and reasoning to navigate the world effectively.
As Gary Marcus, author of The Algebraic Mind, eloquently writes:
“To build a robust, knowledge-driven approach to AI we must have the machinery of symbol manipulation in our toolkit. Too much useful knowledge is abstract to proceed without tools that represent and manipulate abstraction, and to date, the only known machinery that can manipulate such abstract knowledge reliably is the apparatus of symbol manipulation.”
Encouragingly, the limitations of a purely neural approach are gaining recognition, and the field appears to be shifting toward neuro-symbolic methods. The resurgence of interest in knowledge graphs and graph databases, such as Neo4j, reflects this promising trend.
Evolutionary and Genetic Algorithms: Learning from Nature
Another crucial piece of the AGI puzzle lies in adopting genetic and evolutionary algorithms to complement neuro-symbolic methods. Evolution has been nature’s algorithm for creating adaptive intelligence over billions of years. By simulating similar processes, we can explore how intelligence might evolve in artificial systems.
Human intelligence thrives on adaptability, allowing us to navigate complex environments fluidly. Evolutionary algorithms often produce emergent behaviors — unexpected solutions that arise naturally and are difficult to engineer directly. These behaviors can shed light on phenomena like creativity and problem-solving.
Using a process akin to natural selection, we can create self-optimizing systems, much like how species evolve in nature. By introducing novel ideas — akin to “mutations” — into the system, beneficial changes can naturally persist and propagate, while less optimal mutations are naturally discarded. Applying these principles to AGI could enable the development of leaner, more adaptable models.
Consciousness and Understanding
The pursuit of AGI should not be reduced to scaling up models or maximizing benchmarks. It must grapple with profound questions:
What is the nature of consciousness, and can it emerge in artificial systems?
How do we define “understanding,” and how can we measure it?
What ethical considerations arise when developing systems capable of autonomous reasoning?
Current AGI claims often sidestep these questions, focusing instead on marketing their latest incremental advances as revolutionary. This superficial approach risks creating powerful but shallow systems that may perpetuate harm rather than advance our understanding of intelligence.
Towards a Genuine AGI
The dream of AGI is not inherently flawed — but the path we are taking to achieve it is. To claim we are on the cusp of AGI without addressing the core questions of intelligence, reasoning, and consciousness is disingenuous at best and exploitative at worst.
True progress in AGI will require moving beyond the hype of neural networks alone, embracing neuro-symbolic methods, and learning from nature’s evolutionary processes. It will also demand humility, acknowledging the profound mysteries of the human mind and the ethical responsibilities of creating systems that might one day approach such capabilities.
We must reject the empty promises of marketing-driven “AGI” and focus instead on the deeper quest for understanding intelligence — one that combines scientific rigor, interdisciplinary approaches, and a genuine commitment to advancing humanity’s knowledge. Only then can we hope to realize the transformative potential of Artificial General Intelligence.
“As I emerged from prison, I see that Artificial Intelligence is being used to create mass assassinations. Where before there was a difference between assassination and warfare, now the two are conjoined, where many, perhaps the majority of targets in Gaza are bombed as a result of Artificial Intelligence targeting. The connection between Artificial Intelligence and surveillance is important. Artificial Intelligence needs information to come up with targets, or ideas, or propaganda. When we’re talking about the use of Artificial Intelligence to conduct mass assassinations, surveillance data from telephones and internet is key to training those algorithms” — Julian Assange
After decades of development, multiple hype cycles, and several “AI Winters,” Artificial Intelligence is at a critical juncture. According to the prevailing narratives, there are two divergent paths for AI: one leading to dystopia, the other to utopia.
On the one hand, AI promises to deliver unlimited productivity improvements, freeing human labor from tedious tasks and enabling more creative, fulfilling pursuits. AI could potentially solve humanity’s most complex challenges, uncovering groundbreaking solutions hidden in massive datasets.
On the other hand, AI facilitates the mass production of content at negligible cost, creating fertile ground for misinformation and propaganda. Additionally, it amplifies the power of mass surveillance, following the trajectory of earlier technologies like telecommunications and the Internet.
Tracked and Traced
The practice of surveillance, or systematic observation has a long history, intertwined with power. From ancient emperors deploying spies to monitor dissent, to medieval rulers using informants to control their courts, surveillance has long existed as a tool for maintaining authority. Modern advancements in technology has transformed this localized practice into a global infrastructure that systematically strips individuals of their right to privacy.
In the 20th century, during the rise of nation states and world wars, governments established intelligence networks such as Britain’s MI5 and the United States’ Office of Naval Intelligence (ONI). Wiretapping became a key surveillance method, often conducted without warrants or consent. This invasive practice was justified in the name of the “greater good,” such as catching criminals or safeguarding national security.
During the Cold War era, state surveillance expanded dramatically. The U.S. National Security Agency (NSA) grew in scope, with its activities justified by the fight against Communism (The Red Scare). Programs like COINTELPRO (Counter Intelligence Program) targeted civil rights activists, anti-war protesters, and even cultural figures like Martin Luther King Jr. In the 1970s, the Church Committee — a U.S. Senate investigation — exposed decades of unconstitutional surveillance practices, revealing a troubling history of government overreach against its own citizens.
So Many Eyes
The late 20th century ushered in advancements like cell phones and the Internet, providing even more opportunities for surveillance. Intelligence agencies began tapping not just phone calls but also text messages, emails, and other online activities — often without cause and without users’ knowledge.
The September 11 terrorist attacks marked a paradigm shift. In response, the PATRIOT Act authorized unprecedented surveillance powers, transforming targeted observation into mass surveillance. Until whistleblower Edward Snowden’s revelations in 2013, most Americans were unaware of the scale of this intrusion into their privacy.
Big Tech Wants A Piece
In more recent years, big tech companies have become embedded into the machinations of mass surveillance, blurring the lines between private enterprise and state power. One of the largest technology companies, Microsoft, has played a significant role in this evolution, entering into contracts with government that would provide the technological tools to carry out these surveillance programs.
These tools include Microsoft’s Azure cloud platform and AI technologies such as facial recognition and data analytics. Microsoft’s involvement extends beyond the U.S., with partnerships worldwide, including with governments accused of human rights abuses. While Microsoft publicly claims to align with human rights principles, its actions suggest otherwise, underscoring the need for regulation and reform.
Shadows In The Walls: Convenience at a Cost
Amazon’s Alexa device highlights the significant trade-offs individuals are willing to make between privacy and convenience. Users effectively invite a form of constant surveillance, or wiretapping, into what has traditionally been regarded as a sanctuary of privacy. This compromises a principle deeply rooted in human rights, including protections enshrined in the U.S. Constitution and Bill of Rights, which uphold the home as a place shielded from intrusion. Amazon has faced scrutiny on how it collects, stores and uses data from Alexa and other devices. Many users are unaware of how much information is being gathered or how to delete recordings permanently. Alexa and similar devices contribute to what privacy advocates call the “normalization of surveillance.” By embedding microphones, cameras, and AI assistants into daily life, companies like Amazon make constant data collection seem routine and unremarkable.
AI Ramps It Up
Recently, OpenAI announced new product enhancements, including “advanced voice mode” and features involving cellphone camera integration. Simultaneously, both OpenAI and Anthropic secured deals with the U.S. government to research and test their AI models. Notably, OpenAI appointed ex-NSA director Paul M. Nakasone to its board of directors in April 2024.
In November 2024, Anthropic partnered with Palantir — a company synonymous with mass surveillance — and Amazon AWS to use its Claude language model for processing classified government data. These developments starkly contrast Anthropic’s public messaging about AI safety and existential risk, raising serious concerns about corporate-government alliances and their implications for privacy.
A Fork In The Road
The marriage of Artificial Intelligence with mass surveillance presents a stark crossroads for humanity. AI’s power to analyze and act on vast datasets is unparalleled, but its use in targeting, propaganda, and pervasive surveillance raises critical ethical questions. The technologies once hailed as tools for liberation are increasingly turned into instruments of control, blurring the lines between convenience, safety, and oppression.
As citizens, we must resist the normalization of surveillance and demand transparency, accountability, and regulation of both governments and corporations wielding these tools. The path AI takes — utopian or dystopian — will depend on the values we embed in its design, deployment, and governance. Without concerted effort, we risk surrendering not just our privacy, but our agency, to systems that view humanity as data points rather than individuals.
History reminds us that unchecked power leads to abuse. The revelations of COINTELPRO, the PATRIOT Act, and the Snowden leaks were not aberrations but predictable outcomes of systems built without oversight. Today, the stakes are even higher. The question we face is not just whether AI will be used for good or ill, but whether we as a society will demand that it serves humanity’s collective interests rather than undermining them.
The choice is ours to make — while we still can.
For most of my life, I have struggled with mental health challenges, including anxiety and depression.
These challenges have had profound effects on my life — making it difficult to maintain relationships, keep jobs, and sometimes even manage everyday tasks that many take for granted. I’ve seen friends struggle with the same issues and, tragically, lost some because of it. I know these stories are not unique. So many of us carry them, often in silence.
Too many people face these battles alone due to the persistent stigma surrounding mental health. Even for those ready to seek help, accessibility is a major hurdle — whether due to cost, lack of resources, or other barriers. As rates of anxiety, depression, and suicide continue to rise, access to support services has only become harder.
Park Bench is an innovative, AI-powered platform designed to offer a safe, private, and free space for personal reflection and support.
Whether through text-based chat or revolutionary AI-generated video responses, Park Bench provides a space where you can feel heard and supported, judgment-free.
If you’re curious, take a look around and give it a try. If you’re interested in generating a video, I’d love for you to reach out to me first — these require my laptop to process and are computationally intensive. You can email me at michael@parkbench.ai.
I’d deeply appreciate any feedback, support, or thoughts you might have. Together, we can help create spaces where no one feels alone in their mental health journey.
Thank you.
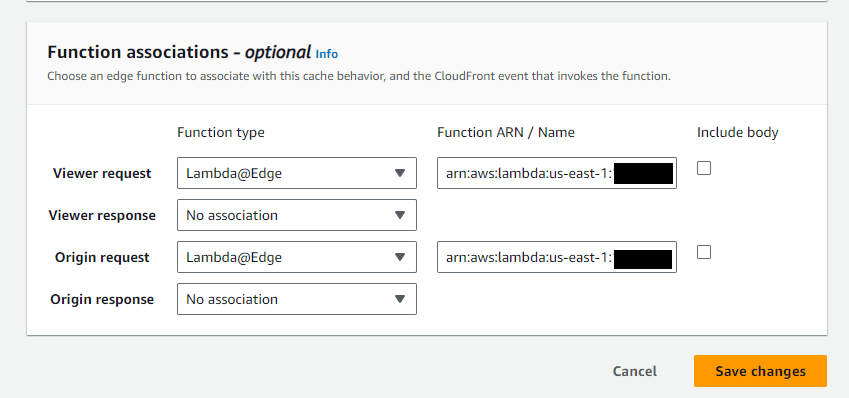
Single-Page Applications (SPAs) are popular for their fast and seamless user experiences. However, SPAs often struggle with SEO because search engine crawlers can’t easily render JavaScript-heavy pages. This can result in poor indexing and missed traffic opportunities. While frameworks like Next.js offer a built-in solution with server-side rendering (SSR) to address this issue, not all projects are built with these frameworks. Fortunately, services like Prerender.io and AWS Lambda@Edge provide a flexible and powerful alternative to achieve similar results, even without SSR.
In this guide, I’ll walk you through how I used Lambda@Edge to intercept bot requests for my SPA and route them to Prerender.io to generate static, SEO-friendly content.
The Challenge with SPAs
SPAs rely heavily on client-side JavaScript, which can create a blank page when crawlers like Googlebot or Twitterbot visit. While modern crawlers can render JavaScript to some extent, it’s inconsistent and slow. To fix this, we can send pre-rendered content from Prerender.io when bots visit the site.
In my case, I was building social preview cards (using OpenGraph meta tags) dynamically for my website. On the front-end, I used the react-helmet library to inject these meta tags for different pages.
What is Prerender.io?
Prerender.io is a service that renders your JavaScript SPA as a static HTML snapshot. When crawlers visit your site, you can serve these static pages, ensuring the bots can easily read your content and index your site correctly.
What is Lambda@Edge?
Lambda@Edge, an AWS service, allows you to execute code at AWS’s edge locations (CloudFront) in response to events, such as HTTP requests. This makes it perfect for intercepting requests from bots and rerouting them to Prerender.io without adding latency for regular users. It ensures that only crawlers see the pre-rendered pages, while real users still experience the dynamic, JavaScript-driven SPA.
Setup
First, ensure that you have deployed your website content to S3 and have it served through CloudFront.
Create an account on Prerender.io and grab the API Key. Since CloudFront integration is not officially supported, you can skip the setup wizard and go straight to AWS to create Lambda@Edge functions. There are two functions to set up: one for a viewer request and one for an origin request.
Viewer Request
A Viewer Request event occurs when CloudFront receives a request from the viewer, such as a browser or bot/crawler. By attaching a Lambda@Edge function to the Viewer Request on our CloudFront Distribution, we can modify the incoming request before it is sent to the origin (like a web server or S3 for the SPA).
Our viewer request lambda function detects whether the request is coming from a bot/crawler based on request headers and adds the following headers:
X-Prerender-Token: Set to the API Token from Prerender.io
X-Prerender-Host: Set to the domain for your website
X-Prerender-Injected-Data: In my case, used to inject OpenGraph meta tags via react-helmet (set to true)
The host is also updated to ensure it points to your website, not S3. Make sure to go to your CloudFront distribution and add these custom headers under Cache key and origin requests > Legacy cache settings > Headers.
Since AWS requires Lambda@Edge functions to be in the us-east-2 region, create a new Node.js Lambda function. The Lambda@Edge function looks as follows:
In CloudFront, Lambda@Edge functions must be referenced by a version, so after deploying a new version, you need to update the ARN in CloudFront, or you can deploy the Lambda function as Lambda@Edge from the Lambda console, although this may be buggy.
Origin Request
An Origin Request event happens right before CloudFront forwards a request to the origin (S3, web server, etc.). We can further modify the request here before it reaches the server.
This Lambda@Edge function has a different context from the Viewer Request. It checks for the headers added from the Viewer Request function and modifies the origin if it’s a pre-render request:
Since Lambda@Edge functions can execute in different regions based on the client’s location, finding logs can be tricky. You may need to navigate through different regions in CloudWatch to find logs for specific requests.
You can verify the association of your Lambda@Edge functions with your CloudFront Distribution by navigating to Function Associations under the default behavior.
To test, simulate a bot request using a command like:
curl -v -A "twitterbot" <URL to test>
If you see a 404 error, it may be because CloudFront is pointing to S3 for a dynamic route. You can set up a custom 404 response to return a 200 status code and use the pre-rendered content as the response body.
For testing social previews, you can use these tools:
By leveraging AWS Lambda@Edge and Prerender.io, you can ensure that your SPA is fast for users and SEO-friendly for crawlers. In my case, I was able to generate dynamic social preview cards. This solution is scalable, low-maintenance, and significantly boosts your website’s discoverability.